
쓰레드와 멀티스레드 이해하기
[단일쓰레드가 아닌 멀티쓰레드를 사용하는 이유]
쓰레드는 프로세스(실행중인 프로그램)에서 하나의 실행 흐름으로 프로그램 실행의 가장 작은 단위다. Java 명령어를 사용해 클래스를 실행하면 JVM이 시작되며, 자바 프로세스가 생성된다. 이때, main() 메서드가 실행되면서 하나의 기본 스레드(메인 스레드)가 시작된다.
일반적으로 하나의 쓰레드만으로는 동시에 여러 작업을 하는데 제한이 있으므로, 긴 대기시간이 발생했을 때 기다리는 동안 다른 일을 처리할 수 없다. 따라서 이러한 문제를 해결하기 위해 하나의 프로세스 내에서 여러 개의 스레드를 동시에 실행하는 방식인 멀티쓰레드를 사용하해 CPU를 효율적으로 사용할 수 있다. 멀티쓰레드를 이용하면 쓰레드가 빠르게 번갈아가며 작업을 처리하는 동시성 프로그래밍이 가능해진다. (싱글코어 기준 설명)
[멀티프로세스 vs 멀티쓰레드]
- 멀티프로세스(Multi-Process): 하나의 작업을 동시에 수행하기 위해 여러 개의 JVM(프로세스)를 실행하는 방식
- 멀티쓰레드(Multi-Thread): 하나의 JVM(프로세스) 안에서 여러 개의 쓰레드가 메모리를 공유하며 동시에 작업하는 방식
멀티 프로세스가 아닌 멀티쓰레드방식이 고려되는 이유는 프로세스가 하나를 시작하려면 많은 자원(Resource) 가 필요하고, 프로세스간 Context Switching 비용 등 오버헤드가 멀티쓰레드방식보다 크기 때문이다.
메모리 공유 여부 측면에서 멀티프로세스는 각 프로세스마다 독립적인 메모리 공간이 필요하고 데이터를 주고받기 위해서는 IPC(Inter Process Communication)가 필요하다. 반면 멀티스레드는 스레드마다 Stack과 PC Register는 별도로 할당되지만, Heap과 Method Area를 공유해 메모리 사용 효율이 높다. (JVM 메모리 구조 기준 설명)
생성시 필요한 메모리 관점에서 JVM을 기본적으로 아무 옵션 없이 실행하면 적어도 32MB ~ 64MB 의 물리메모리를 점유하게 된다. 그에 반해 쓰레드를 하나 추가하면 1MB 이내의 메모리를 점유한다. 그래서 쓰레드를 "경량 프로세스"라고도 부른다 (자바의 신 vol2 147p)
Thread 클래스와 Runnable 인터페이스
[간략히 정리하는 자바 버전별 동시성 프로그래밍 변화]
자바는 초기 버전 부터 멀티스레드 프로그래밍이 가능하도록 Thread 클래스와 Runnable 인터페이스를 제공했다. 멀티스레드 프로그래밍의 기본적인 형태였으나, 스레드 관리, 반환값 처리, 예외 처리 등에 제약이 많았다.
JDK 1.5 (Java5) 부터 concurrency API 가 많이 추가되었다. (java.util.concurrent 패키지) Executor, Callable, Future 가 도입되었다.
- Executor와 Thread Pool 지원을 통해 쓰레드 재사용이 가능해졌고, ExecutorService로 스레드 관리 및 종료가 용이해졌다.
- Callable과 Future가 추가되어 스레드 작업의 결과 반환 및 예외 처리가 가능해졌다. (기존 Runnable은 void만 반환 가능)
JDK 1.7 (Java7) 부터 Fork/Join Framework 가 도입되었고 RecursiveTask 과 RecursiveAction 이 제공되었다.
- Fork/Join 프레임워크(java.util.concurrent.ForkJoinPool) 추가되어 재귀적인 병렬 처리(Divide and Conquer)가 가능해졌다.
JDK 1.8 (Java8) 부터 CompletableFuture 가 도입되었다.
- 비동기(Asynchronous) 프로그래밍을 가능하게하는 CompletableFuture 인터페이스가 도입되었고 람다 및 체이닝(thenApply, thenAccept) 를 이용해 간결하게 작성이 가능해졌다.
Java 9 부터 리액티브 프로그래밍을 제공하는 Flow 클래스가 도입되었다. (java.util.concurrent.Flow)
- Reactive Streams 표준에 따라 publish-subscribe 모델을 사용할 수 있게 되었다.
[쓰레드를 구현하는 방법]
자바에서는 작업 스레드도 객체로 생성되므로 클래스가 필요하다. 쓰레드를 구현하는 것은 크게 두 가지 방법이 있다.
- Runnable 인터페이스를 사용한다.
- Thread 클래스를 사용한다.
Thread 클래스는 Runnable 인터페이스를 구현한 클래스다.

Runnable 은 run 메서드만 가진 함수형 인터페이스다.

public class ThreadSample extends Thread {
public void run() {
System.out.println("Thread run():" + Thread.currentThread().getName());
}
}
public class RunnableSample implements Runnable {
public void run() {
System.out.println("Runnable run()" + Thread.currentThread().getName());
}
}둘중 어느 방법으로 쓰레드를 구현해도, 작업하고자 하는 내용을 run() 에 작성하면 된다.
[Thread 클래스의 생성자]
java.lang.Thread 클래스에는 다양한 용도로 사용될 수 있는 여러 생성자가 선언되어 있다. 그중 일부는 다음과 같다.
- Thread(): 인자가 없는 기본 생성자
- Thread(String name): 스레드의 이름을 지정
- Thread(Runnable r): Runnable 객체의 참조를 이용
- Thread(Runnable r, String name): "", 이름 지정
[언제 Thread 를, 언제 Runnable 을 사용해야 할까?]
- 쓰레드로 만들어야 하는 클래스가 다른 클래스를 상속받아야 하는 상황이고, 부모클래스가 Thread 를 extends 하지 않았다면 Runnable 인터페이스를 이용한다.
- 쓰레드로 만들어야 하는 클래스가 다른 클래스를 확장할 필요가 없다면 Thread 클래스를 바로 extends 해 사용하는 것이 편하다.
자바에서는 다중상속이 불가능하므로 쓰레드로 구현하려면 Thread 클래스만 상속받아야 한다. 따라서 부모 클래스가 thread 를 상속받지 않는 상황에서 자식 클래스를 쓰레드로 만들 수 있는 방법이 없다. 이럴때는 Runnable 인터페이스를 사용해야 한다.
쓰레드 생성 및 시작
[쓰레드 생성 및 시작]
Thread 클래스를 상속받은 경우와 Runnable 인터페이스를 구현한 경우 인스턴스 생성 방법이 다르다.
Runnable 인터페이스를 구현한 경우, Runnable 인터페이스를 구현한 클래스의 인스턴스를 생성한 다음, 이 인스턴스를 Thread 클래스의 생성자의 매개변수로 제공해야 한다.
public static void main(String[] args) {
System.out.println("Main: " + Thread.currentThread().getName());
Runnable runnable = new RunnableSample();
// Thread 클래스의 생성자 매개변수로 runnable 인스턴스를 제공
new Thread(runnable).start();
Thread thread = new ThreadSample();
thread.start();
}
main 스레드와 별도 스레드들이 각각 실행되는 것을 확인할 수 있다.

Runnable 은 함수형 인터페이스이므로 람다 표현식을 이용해 조금 더 간결하게 작성할 수 있다.
Runnable runnable = () -> System.out.println("Thread run():" + Thread.currentThread().getName());
new Thread(runnable).start();
쓰레드를 생성 후 start() 메서드를 호출하면 실행대기상태가 되며 OS 의 스케줄러가 작성한 스케줄에 의해 실행된다.
한 번 실행이 종료된 쓰레드는 다시 실행할 수 없으며, 하나의 쓰레드에 대해 start() 는 한 번만 호출될 수 있다. 하나의 쓰레드에 대해 start() 를 두번 이상 호출하면 IllegalThreadStateException 이 발생한다.

만약 쓰레드의 작업을 한 번 더 수행해야 한다면 새로운 쓰레드를 생성한 다음 start() 를 호출해야 한다.
[쓰레드를 실행시킬때 왜 run() 이 아닌 start() 를 호출하는가?]
main 메서드에서 run 을 호출하는 것과 start 를 호출하는 것은 차이가 있다.
- run(): 생성된 쓰레드를 실행시키는 것이 아니라, 단순히 클래스에 선언된 메서드를 호출하는 것
- start(): 새로운 쓰레드가 작업을 실행하는데 필요한 call stack 을 생성한 다음 run() 을 호출해 생성된 호출스택에 run() 이 첫 번째로 올림 -> 하나의 쓰레드를 JVM 에 추가해 실행
run() 을 직접 호출하면 새로운 스레드가 생성되지 않고 main 스레드(현재 스레드) 의 Call Stack에 올라가 실행된다.

반면 start() 는 새로운 스레드를 만들고, run() 을 새로운 스레드의 Call Stack 에 올려(push) 실행되게 한다. 그래서 run() 이 아닌 start() 를 호출한다.
[start() 는 어떻게 동작하는가?]

start() 의 코드를 보면 다음 과정으로 진행된다.
- 스레드 상태 확인 (0 이면 NEW 상태) -> 0 이 아니면 IllegalThreadStateException
- 스레드 그룹에 추가
- Native 메서드(start0()) 호출 → 실제 OS 스레드 생성
start0() 내부에서 JVM이 OS에게 스레드 생성을 요청하고, 실행을 관리한다.
[ThreadGroup 이란?]
쓰레드 그룹은 서로 관련된 쓰레드를 그룹으로 다루기 위한 것으로, 쓰레드를 그룹으로 묶어서 관리할 수 있다. Java 에서 생성되는 쓰레드들은 모두 어떤 쓰레드그룹에 속해 있다.
JVM 이 시작되면 system 스레드그룹이 생성된다. GC 를 담당하는 Finalizer 스레드를 비롯해 JVM 운영에 필요한 몇 가지 쓰레드들이 생성되어 system 그룹에 포함된다. 이후 system 그룹의 하위 그룹으로 main 쓰레드 그룹이 생성되고 main 메서드를 실행하는 main 스레드가 포함된다.
새로운 쓰레드를 생성할 때 쓰레드그룹을 지정할 수 있으며, 지정하지 않았다면 쓰레드를 생성하는 쓰레드가 포함된 쓰레드그룹에 기본적으로 속하게 된다.
public static void main(String[] args) {
// 메인 쓰레드 그룹
ThreadGroup mainThreadGroup = Thread.currentThread().getThreadGroup();
ThreadGroup systemGroup = mainThreadGroup.getParent();
// 첫 번째 쓰레드 그룹 생성
ThreadGroup groupA = new ThreadGroup("GroupA");
// 현재 실행 중인 쓰레드의 부모 그룹을 가져와서 새로운 그룹 생성
ThreadGroup groupB = new ThreadGroup(systemGroup, "GroupB");
// 그룹 A에 속하는 쓰레드 생성
Thread thread1 = new Thread(groupA,"Thread-A1");
// 그룹 B에 속하는 쓰레드 생성
Thread thread2 = new Thread(groupB, "Thread-B1");
// 쓰레드 그룹 정보 출력
System.out.println("main Thread 의 그룹: " + mainThreadGroup.getName());
System.out.println("main Thread 의 부모 그룹: " + systemGroup.getName());
System.out.println("Thread 1의 그룹: " + thread1.getThreadGroup().getName());
System.out.println("Thread 1의 부모 그룹: " + thread1.getThreadGroup().getParent().getName());
System.out.println("Thread 2의 그룹: " + thread2.getThreadGroup().getName());
System.out.println("Thread 2의 부모 그룹: " + thread2.getThreadGroup().getParent().getName());
}

[Thread.start() 호출 후, run()이 끝날 때까지 기다릴까?]
기본적으로 자바 언어는 sequential 하게 실행된다. 반드시 한 줄의 코드가 있으면 그 줄의 실행이 끝날 때까지 기다렸다가 다음 줄이 실행된다. 하지만 쓰레드의 start() 를 호출하면 시작한 쓰레드의 run() 메서드가 끝날 때까지 기다리지 않고, 바로 다음 줄로 넘어간다. 즉, 호출 즉시 리턴되는 비동기 방식으로 동작한다.
public void runMultiThread() {
RunnableSample[] runnableArr= new RunnableSample[5];
ThreadSample[] threadArr = new ThreadSample[5];
IntStream.range(0,5).forEach(i -> {
runnableArr[i] = new RunnableSample();
threadArr[i] = new ThreadSample();
new Thread(runnableArr[i]).start();
threadArr[i].start();
});
System.out.println("RunMultiThreads.runMultiThread() method is ended.");
}

쓰레드에 이름을 지정하지 않으면 그 쓰레드의 이름은 Thread-n 이다. (n 은 쓰레드가 생성된 순서) 각각 run() 이 끝날때까지 기다리고 다음으로 넘어갔다면 Thread-0, Thread-1 ... 처럼 순차적으로 나오고, 메인쓰레드의 종료출력이 맨 마지막이 되어야 한다. 결론적으로, 쓰레드는 실행순서가 보장되지 않는다. start() 메서드를 호출하면 JVM이 새로운 OS 스레드를 생성 후 실행 대기 상태(Runnable)로 보내고, 실행 대기 상태의 스레드는 CPU 스케줄러의 스케줄링 정책에 따라 실행되기 때문이다.
- start() 로 생성 후 Runnable상태 -> 바로 다음줄 실행
- Runnable 상태인 쓰레드들은 스케줄링 정책에 따라 실행
[쓰레드 우선순위]
쓰레드의 우선순위는 값에 따라 쓰레드가 얻는 실행시간을 결정하기위한 옵션이다. 쓰레드가 수행하는 작업의 중요도에 따라 쓰레드의 우선순위를 서로 다르게 지정해 특정 쓰레드가 더 많은 작업시간을 가지도록 할 수 있다. setPriority() 메서드로 쓰레드 우선순위를 지정한 다음 start() 를 호출하면 우선순위가 반영되어 실행된다.
쓰레드가 가질 수 있는 우선순위 범위는 1~10 이며 숫자가 높을수록 우선순위가 높다. 쓰레드의 우선순위는 기본적으로 쓰레드를 생성한 쓰레드로부터 상속받는다. 예를들어 main 메서드를 수행하는 쓰레드는 우선순위가 5이므로 main 메서드내에서 생성하는 쓰레드의 우선순위는 별도로 지정하지 않는다면 동일하게 5가 된다.
쓰레드 우선순위를 설정한다 해서 높은 우선순위의 쓰레드가 무조건 더 많은 실행시간과 실행기회를 가지게 될 것이라 기대할 수 없다. 자바는 쓰레드가 우선순위에 따라 어떻게 다르게 처리되어야 하는지에 대해 강제하지 않으므로 쓰레드의 우선순위와 관련된 구현이 JVM 마다 다를 수 있다. 또한 현대 컴퓨터는 대부분 멀티코어이므로 하나의 코어에서만 쓰레드가 실행되는것이 아니며, OS 마다 다른 방식으로 스케쥴링하기 때문에 어떤 OS에서 실행하느냐에 따라 다른 결과를 얻을 수 있다.
스레드 생명주기 (Thread Life Cycle)
[쓰레드는 어떤 상태를 가질 수 있을까?]
쓰레드는 생성된 후 종료될 때까지 여러 상태를 가질 수 있다. 자바의 Thread 클래스에는 State 라는 enum이 있다.

| NEW | new Thread() 생성 후, start() 호출 전 |
| RUNNABLE | start() 실행 후, 실행 가능 상태 |
| BLOCKED | 다른 스레드가 락을 잡고 있어 대기 중 (모니터 lock 풀릴때까지 대기중) |
| WAITING | timeout 없이 wait() 또는 join() 으로 무기한 대기중 |
| TIMED_WAITING | sleep() 또는 wait(timeout), join(timeout) 으로 일정시간 대기중 |
| TERMINATED | run() 메서드가 종료됨 (스레드 종료) |
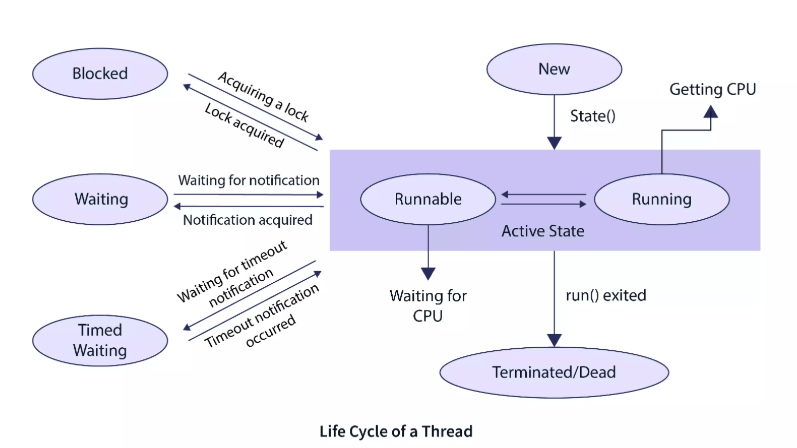
New:
스레드가 생성되었지만 아직 start() 메서드가 호출되지 않은 상태를 의미한다
Active:
start() 메서드가 호출되면 New 상태에서 Active 상태로 전환된다. Active 상태의 스레드는 Runnable 상태 또는 Running 상태일 수 있다.
Runnable:
스레드가 실행될 준비가 되었지만, 실행 대기 중인 상태다. 스레드가 실행될 준비가 되었더라도, 실제 CPU 자원을 할당받기 전까지는 Runnable 상태에서 대기한다. 실행 가능한 스레드들은 스레드 스케줄러(Thread Scheduler)의 관리 하에 대기 큐에 존재한다.
Running:
스레드가 CPU를 할당받아 실행 중인 상태다. 자바에서는 한 스레드가 일정 시간 동안 실행되도록 시간 할당(Time Slice)이 이루어진다.
Waiting:
스레드가 일정 시간 동안 비활성 상태로 전환되는 경우다. 예를 들어, 메인 스레드가 join()을 호출하면, 자식 스레드가 실행을 완료할 때까지 Waiting 상태가 된다. 자식 스레드의 실행이 끝나면, 메인 스레드는 다시 Active 상태로 돌아간다.
Blocking:
특정 스레드가 공유 데이터에 접근하려 할 때, 다른 스레드가 해당 데이터를 사용 중이라면 해당 스레드는 대기 상태(Blocked)로 전환된다. 모니터락(Lock)을 획득할 수 있을 때까지 Blocked 상태에서 기다리게 된다.
Timed Waiting:
특정 조건에 의해 일정 시간 동안 기다리는 상태다. sleep(), wait(timeout), join(timeout)과 같은 메서드를 호출하면 Timed Waiting 상태로 전환된다. 설정된 시간이 지나거나, 필요한 리소스를 획득하면 Active 상태로 복귀한다.
Terminated:
스레드가 실행을 완료하면 Terminated(종료) 상태가 된다. 실행 중 예외가 발생하여 비정상적으로 종료될 수도 있다. 스레드가 종료된 후에는 다시 실행할 수 없다.
[쓰레드 실행 제어 메서드]
Thread 는 기본적으로 다음과 같은 주요 메서드들을 제공한다.
| start() | 새로운 스레드를 생성하고 실행시킨다. (run()을 비동기적으로 실행) |
| join() | 해당 스레드가 종료될 때까지 현재 스레드를 대기시킨다. |
| sleep(ms) | 지정된 시간(ms) 동안 현재 스레드를 일시 정지한다. |
| yield() | 현재 실행 중인 스레드를 잠시 멈추고, 다른 스레드에게 실행 기회를 양보한다. |
| interrupt() | 실행 중인 스레드에 인터럽트 신호를 보내 중단을 요청한다. |
또한 Object 클래스에도 쓰레드의 상태를 통제하는 메서드가 존재한다.
| wait() | 다른쓰레드가0bject 객체에대한notify() 메소드 나notifyAll() 을 호출할 때까지 현재쓰레드가 대기하고 있도록 한다. |
| notify() | 0bject 객체의 모니터에 대기하고 있는 단일쓰레드를 깨운다. |
| notifyAll() | 0bject 객체의모니터에대기하고있는모든쓰레드를 깨운다. |
wait() 의 경우 오버로딩된 메서드가 2개 더 존재한다.
- wait(long timeout): 밀리초 대기
- wait (long timeout, int nanos): 밀리초+나노초 대기

join:
쓰레드의 협업이나 쓰레드 간의 선후 관계가 있을 때 주로 사용한다. join() 을 호출하면 쓰레드가 하던 작업을 잠시 멈추고 다른 쓰레드가 지정된 시간 동안 작업을 수행하게 된다. 시간을 지정하지 않으면 해당 쓰레드가 작업을 모두 마칠 때까지 기다린다.
예를 들어 쓰레드A 가 쓰레드B 가 끝나고 나서 작업을 진행할 수 있다면 A 의 run() 부분에 B.join() 메서드를 호출하면 Waiting(시간시정시 Timed Waiting) 상태로 대기하게 되고, B가 끝나거나 time interrupt(시간지정시)가 발생할 경우 Runnable 상태로 전환된다.
yield:

yield() 는 쓰레드에게 주어진 실행시간을 다음 쓰레드에게 양보(yield) 한다. 예를 들어 스케줄러에 의해 1초의 실행시간을 할당받은 쓰레드가 0.5초의 시간동안 작업한 상태에서 yield() 가 호출되면 나머지 0.5초는 포기하고 다시 실행대기상태가 된다. CPU를 과도하게 사용하는 스레드 간의 상대적인 진행 속도를 개선하려는 휴리스틱(heuristic)적인 방법이며, CPU 사용률이 높은 스레드들이 효율적으로 실행될 수 있도록 하는 것이 목적이지만 실제 효과를 보장하려면 프로파일링 및 벤치마킹과 함께 사용되어야 한다. (거의 사용되지 않는다)
interrupt():
인터럽트는 특정 쓰레드에게 하던 일을 멈추도록 중단신호를 보내는 것이다. 작업중인 쓰레드라면 작업을 중지할 수 있도록, 멈춰있는 쓰레드라면 깨워서 작업을 실행할 수 있도록 한다.
즉, 인터럽트는 두 가지 역할을 할 수 있다.
- 실행 중인 쓰레드에 신호를 보내서 종료 여부를 판단하도록 한다.
- isInterrupted() 를 이용한다.
- 멈춰있는 쓰레드를 깨워서 실행가능한(RUNNABLE) 상태로 바꾼다.
- sleep(), wait(), join() 같은 블록 상태에서 즉시 깨어나도록 한다. (InterruptedException 발생)
실행중인 쓰레드에 interrupt 신호를 보내면 isInterrupted() 를 통해 인터럽트를 확인하고, 실행중인 작업블록을 빠져나오도록 할 수 있다. while 문과 함께 사용된다.
Thread thread = new Thread(() -> {
while (!Thread.currentThread().isInterrupted()) { // 인터럽트 상태 체크
System.out.println("실행 중...");
}
System.out.println("인터럽트 감지! 종료합니다.");
});
thread.start();
Thread.sleep(3000); // 3초 후 인터럽트 발생
thread.interrupt(); // 인터럽트 신호 보내기
무한루프를 돌고있다가, 3초후 interrupt() 가 호출됨에 따라 isInterrupted() 로 while 문을 빠져나온다.
한 쓰레드가 sleep(), wait(), join() 에 의해 일시정지 상태(WAITING)에 있을 때 이 쓰레드에 대해 interrupt() 를 호출하면 sleep(), wait(), join() 에서 Interrupted Exception 이 발생하고 , 쓰레드는 실행대기상태(RUNNABLE) 로 바뀐다. Interrupt 가 발생한 쓰레드는 예외를 catch 해 다른 작업을 할 수 있다.
public static void main(String[] args) {
Thread thread = new Thread(() -> {
try {
System.out.println("스레드가 5초 동안 sleep 상태로 진입...");
System.out.println("thread.getState() (sleep 전) = " + Thread.currentThread().getState());
Thread.sleep(5000);
System.out.println("스레드가 정상 종료됨"); // 이 부분이 실행되지 않음
} catch (InterruptedException e) {
System.out.println("InterruptedException 발생! 스레드가 깨워짐");
System.out.println("thread.getState() (InterruptedException 발생 시) = " + Thread.currentThread().getState());
}
});
thread.start();
try {
Thread.sleep(1000);
System.out.println("메인 스레드가 interrupt() 호출 전 상태: " + thread.getState());
thread.interrupt();
System.out.println("메인 스레드가 interrupt() 호출");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
InterruptedException 이 발생함에 따라 TIMED_WAITING 상태인 쓰레드가 RUNNABLE 로 변경되는 것을 확인할 수 있다.
여기서 주의해야 할 점은 try, catch 에서 sleep() 이후 문장은 실행되지 않는다는 것이다. InterruptException 이 발생하면 즉시 catch 블록으로 이동하고, catch 블록 이후 코드가 있다면, 거기서부터 실행된다.
추가로, 쓰레드가 시작하기 전이나 종료된 상태에서 interrupt() 를 호출하면 예외나 에러 없이 그냥 다음문장으로 넘어간다.
[쓰레드에서 값을 전달하려면 어떻게 해야 할까?]
run() 에는 매개변수가 없다. super를 호출해 Thread 클래스의 name 을 지정하고, 전달하고 싶은 값은 인스턴스 변수를 사용하면 된다.
public class NamedThread extends Thread {
private int count;
public NamedThread(String name) {
super(name);
}
public void run() {
try {
Thread.sleep(100);
System.out.println(Thread.currentThread().getName() + "종료");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
public void increaseCount() {
System.out.println(Thread.currentThread().getName() + "개수 증가");
count++;
}
public int getCount() {
return count;
}
}
이 경우 생각해봐야 할 부분이 있다. 아래코드를 보면 threads[0] 의 increaseCount 를 호출하고 main 이 Thread0 이 종료될 때까지 join() 으로 대기하고 있으므로 "Thread0 개수증가" 가 2번 출력되고 "Thread0 count: 2" 출력 후 메인쓰레드 종료가 출력될 것이라 생각할 수 있지만
public void runThreads() {
try{
NamedThread[] threads = new NamedThread[10];
IntStream.range(0,5).forEach(i -> {
threads[i] = new NamedThread("Thread"+ i);
threads[i].start();
});
Thread.sleep(1000);
threads[0].increaseCount();
threads[0].increaseCount();
System.out.println(threads[0].getName() + " count: " + threads[0].getCount());
threads[0].join();
System.out.println("메인쓰레드 종료");
} catch (Exception e) {
e.printStackTrace();
}
}
실제 실행 결과를 보면 "main개수증가" 와 "Thread0 count: 2" 가 출력된다.
"main개수증가" 가 출력된 이유는 increaseCount() 를 실행한 쓰레드가 main 쓰레드이기 때문이다. "Thread0 개수증가" 로 출력되기 위해서는 increaseCount()를 run() 내부에서 호출하거나, Runnable을 사용하여 별도의 스레드에서 실행하도록 수정해야 한다.
thread[0].getName() 에서 Thread0 이름이 출력된 이유는 쓰레드 상태(TERMINATED) 와 상관없이 인스턴스변수를 출력했기 때문이다.
- Thread0 실행 -> Thread0 의 run() 이 끝나서 TERMINATED 상태로 변경 -> 메인쓰레드에서 increaseCount() 호출 -> 종료된 Thread0 의 name 과 count 를 main쓰레드에서 출력
- 메서드를 실행할 쓰레드에 run() 에서 호출해야한다.
데몬쓰레드
데몬 스레드(Daemon Thread)는 일반(사용자) 스레드의 실행을 돕거나 보조하는 역할을 하며, 모든 사용자 스레드가 종료되면 자동으로 종료되는 스레드이다. 즉, 메인 스레드나 다른 사용자 스레드가 모두 종료되면 데몬 스레드도 자동으로 종료된다. 자바에서는 setDaemon(true) 메서드를 사용하여 특정 스레드를 데몬 스레드로 설정할 수 있다.
일반적으로 데몬쓰레드는 다음과 같이 백그라운드 작업을 수행하는데 사용된다.
가비지 컬렉터 (Garbage Collector)
자바의 Garbage Collector는 백그라운드에서 실행되는 데몬 스레드로 동작한다. 실행 중인 프로그램의 메모리를 정리하면서도, 모든 사용자 스레드가 종료되면 가비지 컬렉터도 자동 종료된다.
로그 기록(Log Writer)
서버 프로그램에서 실시간으로 로그를 기록하는 스레드를 데몬 스레드로 설정해, 메인 서비스가 종료되면 로그 기록 스레드도 자동 종료되도록 설정할 수 있다.
자동 저장(Auto Save) 기능
문서 편집기에서 일정 간격으로 데이터를 저장하는 백그라운드 스레드를 데몬 스레드로 실행할 수 있다.
public static void main(String[] args) {
Thread daemonThread = new Thread(() -> {
while (true) {
System.out.println("데몬 스레드 실행 중...");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
daemonThread.setDaemon(true); // 데몬 스레드 설정
daemonThread.start();
try {
Thread.sleep(3000); // 메인 스레드 3초 후 종료
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("메인 스레드 종료");
}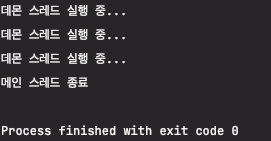
데몬쓰레드는 무한루프를 돌고 있지만, 메인쓰레드가 종료되면서 데몬쓰레드도 강제 종료되는 것을 확인할 수 있다.
Thread 와 Runnable 을 직접 사용할 때 단점 및 한계
Thread와 Runnable을 직접 사용하는 방식은 다음과 같은 한계가 있다.
저수준의 API에 의존함
Thread를 직접 생성하고 관리해야 하므로, 개발자가 스레드 생성과 실행을 직접 제어해야 한다. 반면, ExecutorService를 사용하면 스레드 풀을 활용하여 보다 효율적으로 관리할 수 있다.
반환값을 직접 받을 수 없음
Runnable의 run() 메서드는 반환값이 없기 때문에, 결과를 직접 반환할 수 없다. Callable과 Future를 사용하면 스레드 실행 후 결과를 쉽게 받을 수 있다.
반복적인 스레드 생성과 종료로 인한 오버헤드 존재
Thread는 한 번 실행되면 종료되므로, 반복적인 작업을 수행할 때마다 새로 생성해야 한다. 이는 성능에 부담을 주며, ExecutorService의 스레드 풀(Thread Pool)을 사용하면 이러한 문제를 해결할 수 있다.
스레드 관리의 어려움
여러 개의 스레드를 직접 생성하고 동기화하는 것은 복잡하며, 예외 처리 및 리소스 관리를 직접 해야 한다. ExecutorService를 사용하면 자동으로 스레드를 관리할 수 있어 보다 효율적인 멀티스레딩이 가능하다.
이러한 이유로, Java5 이후부터 Executor, ExecutorService, ScheduledExecutorService, Callable, Future 등의 다양한 API들이 추가되어 더 효과적인 스레드 관리 방법을 지원하고 있다.
'Java' 카테고리의 다른 글
| [Java] 자바 객체의 Lock 과 Monitor 이해하기 (0) | 2025.03.09 |
|---|---|
| [Java] Blocking Queue 이해하고 사용해보기 (1) | 2025.03.07 |
| [Java] Callable, Feature 이해 및 사용예시 (0) | 2025.02.26 |
| [Java] 열거형(Enum) 이해하고 사용하기 (1) | 2025.02.22 |
| 자바의 정석 OOP(1) (0) | 2024.09.23 |